
TLDR: Logging is an extremely important part of every application out there, especially user action logs. Storing them in a database isn't ideal for various reasons, it's advisable to store them in a Data Warehouse like BigQuery or RedShift for analysis and access later.
If you've worked at a slightly established startup or a larger company, you have inevitably come across something very crucial to the business, logging. Not just user logging, even the kind of logging where the users themselves can see a history of actions they performed. For example, Todoist's Activity History or from one of the startups I worked at: Solar Ladder's Activity Logs
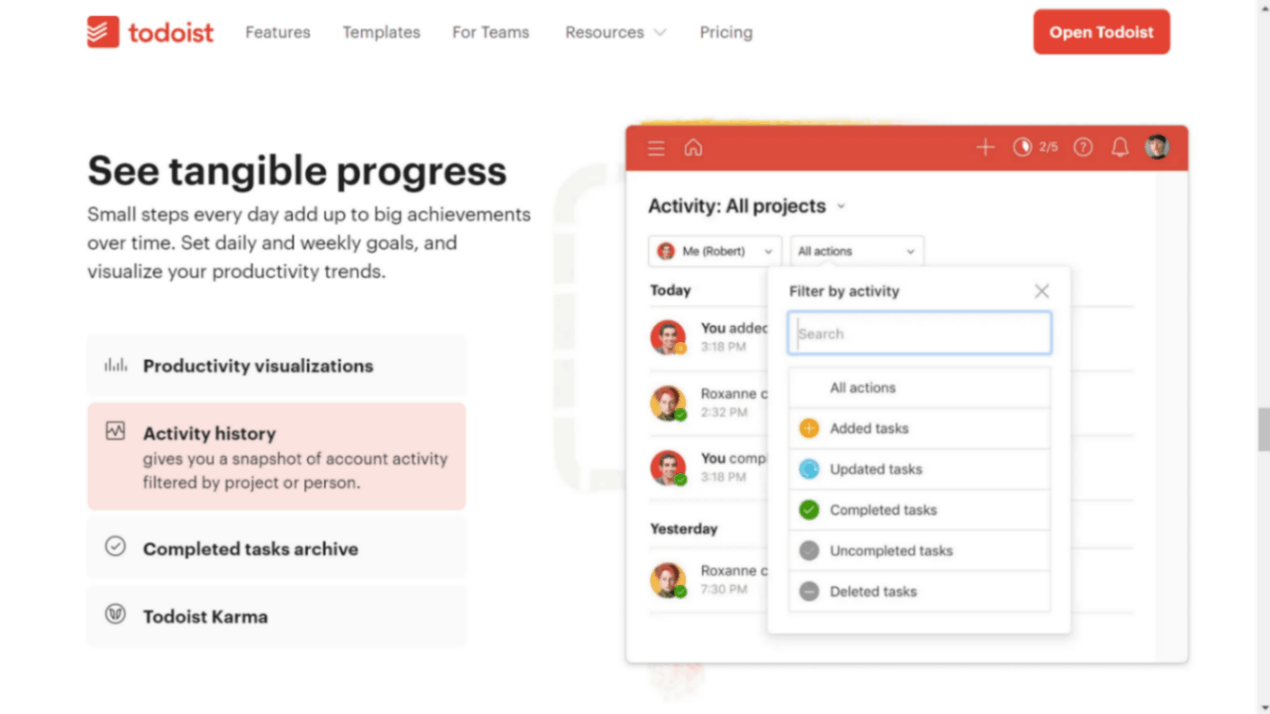
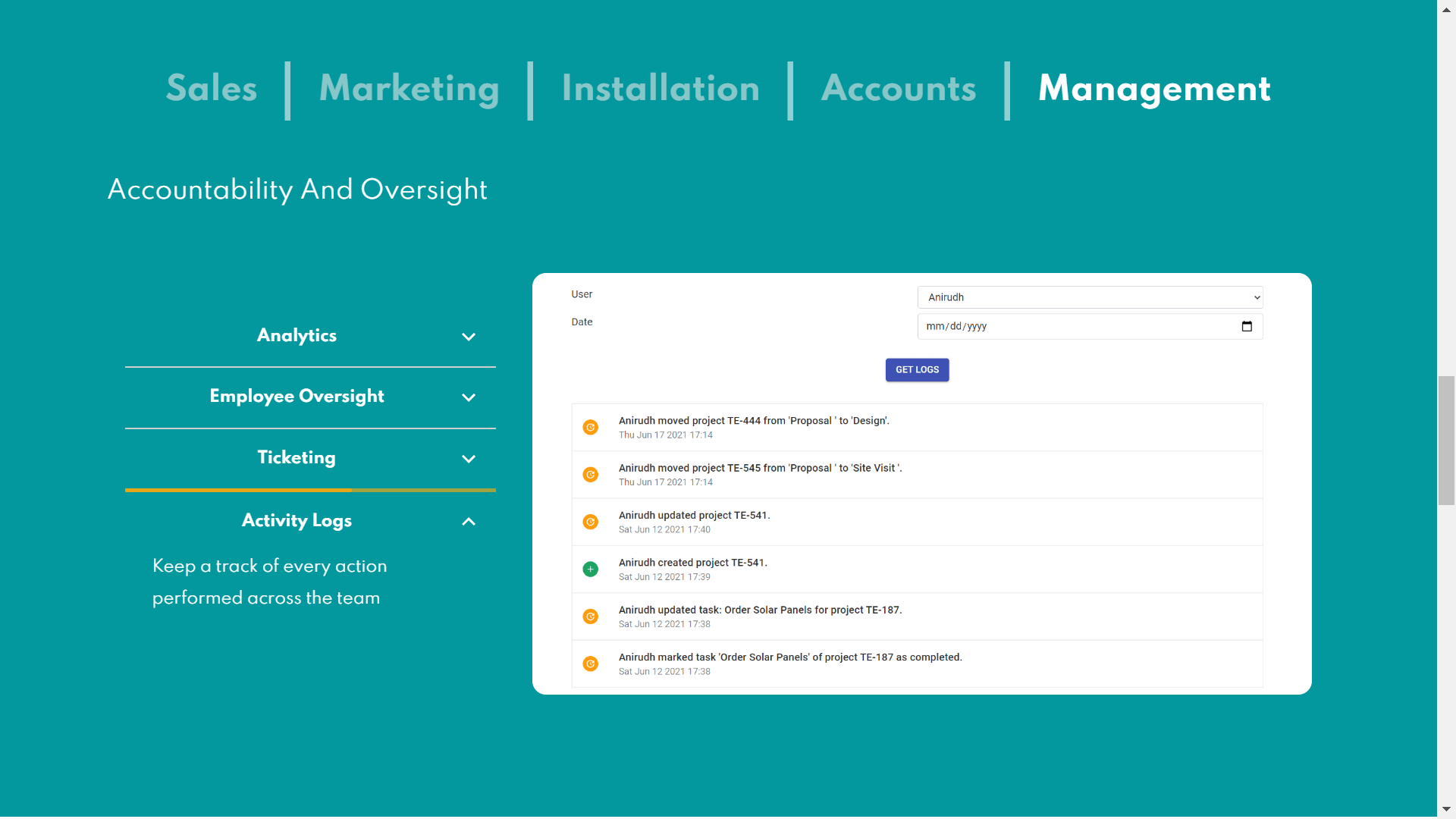
For analytics based on user events, there are solutions available in the market like Amplitude. But for end-user visibility, the go-to option for startups has been to simply log the events to a collection/table in their primary database itself and then expose an endpoint that queries the database table and sends back the logs. This approach is an okay point to start with, but this solution isn't scalable or the recommended one.
For one, logs are the most commonly created entities in the entire system, so it's not surprising if the event logs table becomes the largest table in the database, simply because logs are created more often than any other entity.
Secondly, logs that are older than a specific amount of time, become less valuable for the user and it's highly unlikely that users will ever want to access their activity logs from 2-3 years ago, or even 2-3 months ago, especially if there's no way for them to seek to a specific date.
For example, Instagram Saved only lets you scroll to previously saved posts, for an active user that's used Instagram for over 5 years, it's impossible or impractical to ever be able to access posts they saved over 4 years ago; companies are aware of this, and hence, it does not make sense for logs that are old to be stored on the same storage class as logs that have a high chance of being retrieved.
Since a regular database does not give you the option to split data into different storage classes, based on which you are billed differently, we can turn our heads to Data Warehouses.
Data Warehouses are specially designed systems for storing, retrieving and analysing large amounts of data, say Google's BigQuery or AWS's Redshift. They handle the storage, and class separation of data based on rules you define.
At the startup I worked with earlier, we used to store our logs in MongoDB and we decided to shift those logs to a BigQuery, for all the reasons mentioned earlier.
Enter Google Cloud Logging
If you've used AWS CloudWatch, consider Google Cloud Logging as its GCP Counterpart, it's a great service to store all kinds of logs, structured and unstructured, ranging from Infra level logs to deployment logs to application event logs.
It retains those logs for 90 days in your storage bucket free of charge and provides us with the ability to transfer/route certain records using Log Routers to preferred destinations, it could be a Cloud Function using which you can perform actions, it could be a data warehouse where you want to store logs for a period of longer than 90 days, or anything you can imagine. Your imagination is the limit here.
We can use Google Cloud Logging as an entry point to log entries for our user action logs using its extensive SDKs.
Sending Logs to Google Cloud Logging from your Application
If you've been logging user events for some time in your application, you would usually have a standard track function which you would invoke something like this:
function createEntity () {
... Do the action
// track( eventName, properties );
track(ENTITY_CREATED, { ...user-specific information });
}The endpoint for this track function could be multiple things, it could be sending events to an event pipeline via Segment, it could be tracking events to a service like Google Analytics, or in case you store user action logs, it would be sending data to your backend where you store the information to your database.
All that we have to do at that point is use Google Cloud logging's SDKs and add structured logs for the actions we need.
I've used the Google Cloud Logging Node.js SDK for this purpose.
const { Logging } = require("@google-cloud/logging");
const logging = new Logging({
projectId,
credentials: yourGCPServiceAccountWithAccessToLogging,
});
const logger = logging.log(logName); // Think of logName as a folder in which logs are to be stored.
const logEntry = logger.entry(
{ resource: { type: "global" } },
{
...your event information,
isAppUserEventLog: true,
}
);
logger.write(logEntry);Some references for using Cloud Logging:
- @google-cloud/logging Node.js SDK
- Structured Logging
Transporting Selective Logs to BigQuery
We need to set up the Cloud Logging console to forward logs to a BigQuery dataset. To do so, navigate to your project in Google Cloud Console and further navigate to Cloud Logging.
From the left navigation, navigate to Logging and then to Logs Router. Click on "Create Sink".
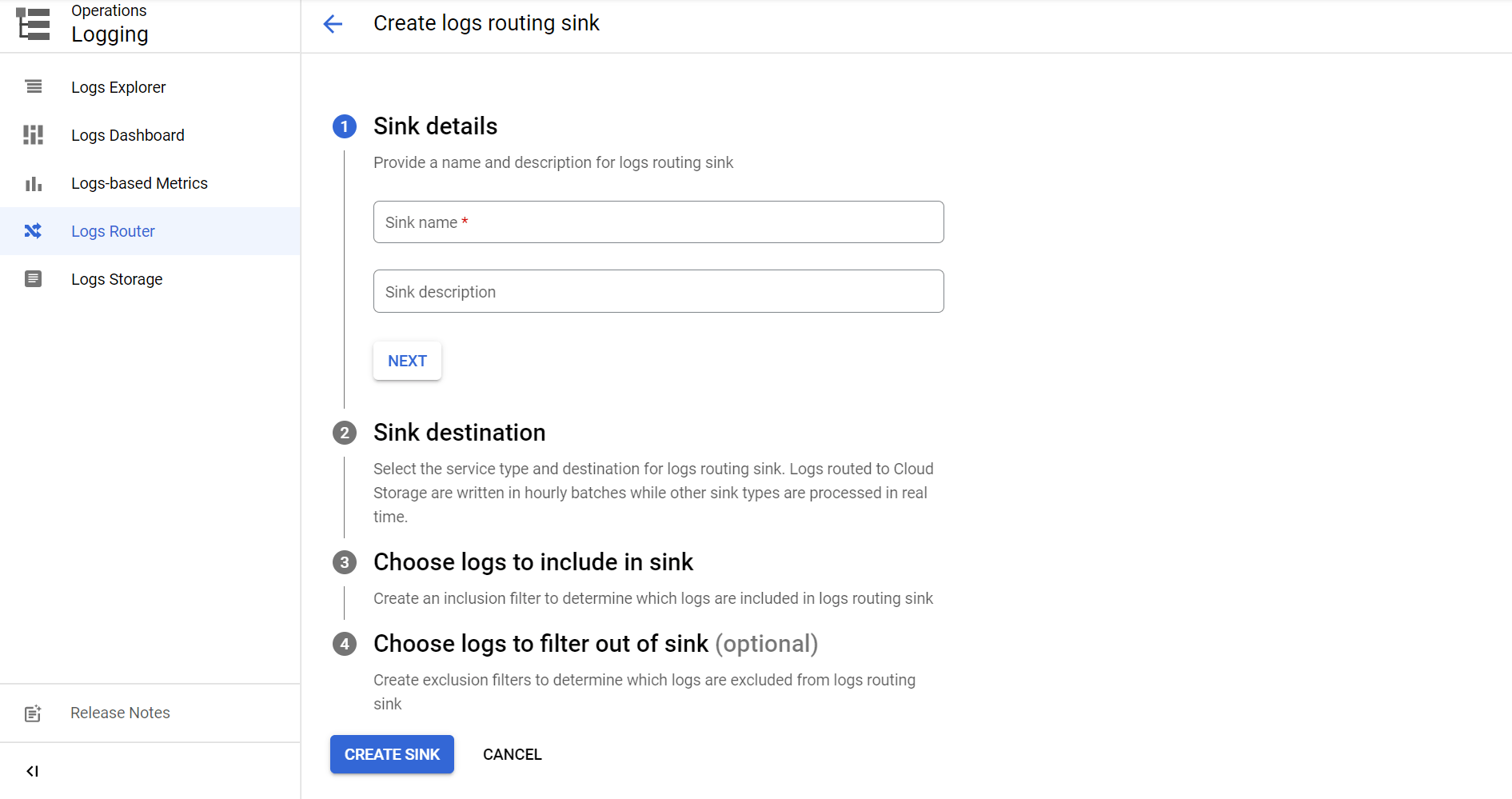
Provide a lowercase sink name, and proceed to the Sink Destination step. In "Select Sink Service", select "BigQuery dataset", and choose the dataset you want to transfer the logs to or create a new one from the options.
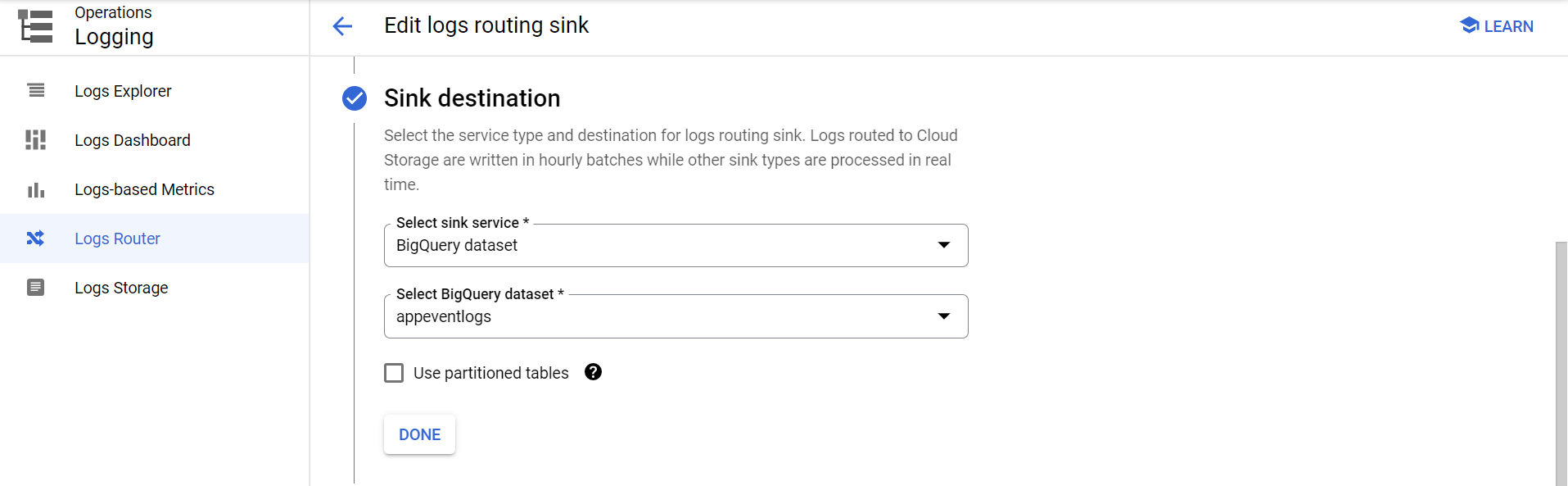
The next step would be to specify the kinds of logs, from the plethora of log types Cloud Logging has, that need to be forwarded to BigQuery:
Inclusion Filters
severity = "INFO" AND
resource.type = "cloud_function" AND
jsonPayload.isAppUserEventLog = trueor if you're not using Cloud Functions, it will simply be
severity = "INFO" AND
jsonPayload.isAppUserEventLog = trueRetrieving Logs For Your Application
BigQuery is completely interoperable with SQL Queries, so you can use SQL Queries to retrieve data for your application or use the BigQuery APIs.
I prefer the Google Cloud BigQuery Node.js SDK for getting the data I need for my application.
Sample BigQuery Query for data from a table
Interoperability
This pattern of application event logging is common and works similarly for stacks in AWS (CloudWatch to AWS RedShift) as well.