
Imagine this, you spend a couple of months building a fantastic web app that takes care of accounting for companies. Being the new-age app it is, it works with the "Cloud", no customer ever has to worry about exporting or saving their data.
Let's assume that the world is an ideal place and the people in it have no problem saving their data to the cloud, the customers would love the product and would not be able to get enough of it. But we don't live in a perfect world.
The product ships out and the customers don't like it, a unanimous complaint is that they must sign in to use the app (After all, how else would you work with the cloud and have the amazing sync capabilities that are the selling point of the product?).
Apart from the fact that the team grossly misunderstood the needs of the market (Accounting firms do not need fancy UIs or Cloud sync, they're dealing with sensitive data that they would like to keep in-house - You wouldn't believe how often products misunderstand their target market), you are now tasked with making changes to the web app in such a way that it can store data on the user's device instead of backing up to the cloud.
You go in, look at all the code you wrote and realize: "Wait a second, due to the deadlines I put a lot of code that couples the logic of having to upload to the cloud with the code".
No shocker, this is an inevitable step every single software goes through, and if you haven't encountered something like this, you haven't built enough software so far (Or you're just too good at implementing all the wonderfully decoupled architecture that so many books and cough cough blog posts are written about)
Nevertheless, it's a task and something has to be done about it, so you research storage methods on the web and add code that gives the user a choice between whether they want to store data on the cloud or their device. With that choice, you add the following logic to all storage functions:
if (user.storageChoice === 'local') return storeInIndexedDB(...);
else return storeOnTheCloud(...);
// And during retrieval
if (user.storageChoice === 'local') return getFromIndexedDB(...);
else return getFromTheCloud(...); There's no shame to admit we've all done this in a hurry at some point in time in our code. And we'll look at what is wrong with this approach.
The app works, it's tested and rolled out. The customers love the update! Go privacy!
Next month, the customers have a realization: If the software can store everything on their device, why not just have it as a desktop app, hell why not allow them to use it without a login and have a licensing fee instead? The CEO agrees with the feedback, agrees to the demands and instructs the team to get working on it with a promised deadline of 2 months with a slight change.
This is a typical example of business policies changing the core nature of the product, the assumptions you make at the beginning of the product are rarely the final decisions the product ends up with. Software is meant to work flexibly with such business logic, it is called "Soft" for a reason.
What started as a web application that syncs data to the cloud, has now turned into a web + desktop application that stores data locally and works without a login. For any application, this is a fundamental change and for applications that are not structured well, it is usually a ground-up rewrite.
For our example, we're fortunate that we have a tech stack that can be ported over to a desktop application framework like Electron. But wait, the developers realize that in even though in principle, the app can be ported over as Electron and the Browser essentially work on the same principles, the porting over will take time due to coupling between features that work on the browser and don't yet work inside Electron + They also have to remove all the login walls associated with app features.
For many apps, this is where the month-long ordeal of porting changes with conditional checks like isElectron() ? Do one thing : Do something else starts.
The growth track for any app
What we saw above is a natural progression of any app out there. In the journey of discovering product-market fit, an app goes through several experiments and multiple pivots because it's challenging to get it right on the first try.
Even for an established product, in an attempt to get to more users, we can see several examples of expansions to new platforms or different types of customers, both of which require either completely new codebases (For example: Supporting Android users for an existing web-app based business) or supporting newer functionality in an existing codebase.
When you're starting with a fresh codebase, or are still very much at the initial stages of a company's history, a business-level pivot can easily justify a new codebase or a rewrite where sins from previous iterations can be washed off. The more the number of decisions that go into an app, often with the amount of time that's passed, the harder it is to justify a rewrite as it not only involves a lot of decisions that you might not have had control over but also just too much to build again, and that's not even accounting for the lost productivity that goes into simply rewriting a codebase.
What we would rather want
Every app developer wants the same thing: I should be able to make changes fast, and easily to an existing codebase. Now that's only possible when your code is structured in a way to reflect two things and reflect them separately:
When you say "I want to be able to show the user their transactions", that's business logic, how you do that is a detail, for instance: I will show the user their transactions by storing and retrieving them in IndexedDB and providing them with a Web Application are all details.
Business Logic and Details should exist independently. This allows you to adjust both your business logic and details with minimal intertwining. Details can be dependent on the business logic (Because some technologies are better at certain things than others) but details dictating business logic ("Oh we are tied up with a NoSQL database and hence this product requirement cannot be done") is a sign of software that has turned "hard".
We can decouple business logic from low-level logic in code via a couple of simple design principles:
Dependency Inversion
It pretty much says: "Always talk to low-level implementations via abstractions."
What does that mean? When you're working with any sort of data storage, have abstractions for operations you want to perform on it and let it handle the underlying implementation details.
The same can be said about working with database operations (If you've used an ORM to simplify data modelling and operations on your DB, that's a good example of this principle).
Dependency Injection
Every played a game on a console? Chances are, you were not given the entire set of games the console supports all at once, practically that's neither possible nor feasible (Unless the console is an utter failure and they're trying to clear their stock).
We instead have to buy a CD for a game or download a game from its store and then play it. We're injecting the game into the console for it to play.
The game exposes boundaries which work with the console's APIs to enable a user to play the game. This is essentially "Dependency Injection".
Technically, even a function argument can be an example of dependency injection. When we talk about Classes and Objects, think of a Car class, it needs wheels, but the wheels can be of any brand. But the only thing the car needs to know is that the wheel has the required components for it to spin and move. Hence, wheel objects like WheelFromBrandA can be injected into the constructor of the Car class.
Now that we have two very important design principles out of the way, let's see how they can help with structuring our app's use cases for extensibility.
Structuring your app around extensibility
Let's look at our hurried if (user.storageChoice === '...') implementation, what's wrong with it?
Well, for starters, it's spaghetti, with each added if statement you make the control flow just a little more complicated and difficult to unravel for future readers of code and most importantly, future refactoring when your business logic inevitably changes.
Let's go back to the days of PHP-based apps, if you're as old or even slightly older than I am, you would have encountered forums that ran on forum software such as phpBB, myBB etc and heck, more than half the world's blogs still run on WordPress which is PHP-based. These forums and blogs were champions of structuring code around composability as they used the concept of "Plugins".
Need to integrate a Facebook login to your app? Simply install the plugin for it and boom, you have a "Login with Facebook" button in your app. Need to add a like button to your forum posts, simply install a plugin to add it. Don't like how your blog looks? Install a theme and voila, your blog looks fresh as new.
These plugins were so well received and so widely adopted that there's a whole ecosystem of programmers who built jobs around custom plugins and theme creation. This is proof that consumers like extensibility, as the selling point of a lot of these blog and forum services was their plugin ecosystem where you're not immediately tied up with something for life. You need a plugin? Add it. Don't need it anymore? Remove it and the app would still work as if the plugin were never installed.
These plugins used both Dependency Inversion and Injection to achieve decoupling. Most of these plugins were injected with the necessary APIs like the Database Class and the APIs for injecting components into the UI.

What we saw above was an example of a user-installed plugin where dependencies are injected. However, a plugin isn't necessarily limited to that. We can have plugins inside our source code. These plugins are enablers of features that lie outside of the app's UI boundary and communicate with the app via classes and expose standardized APIs for the app to consume instead of the app passing down its APIs and the plugin consuming them.
Let's head back to our accounting app and look at how we could clean up our storage solution to escape conditional-hell.
We can have a Storage Manager class that is instantiated with the user's preference (The user preferences will be a separate class if we deal with too many preferences or can be inside the storage manager, totally depends on the use case):
// The storage manager class, a singleton
class StorageManager {
provider: StoragePlugin;
private setProvider (preference: string) {
switch (preference) {
case 'indexeddb':
return (this.provider = new IndexedDBPlugin());
...
default:
// Use a default storage plugin
return (this.provider = new CloudStoragePlugin());
}
}
public initialize (preference: string) {
// Run at the start of the app cycle or whenever the user updates their preference
this.setProvider(preference);
}
}
const storage = new StorageManager();
export default storage;
// In the app
storage.initialize('cloud');
userPreferencesManager.onUserPreferenceChange(function (prev, new) {
if (prev.storage != new.storage) storage.initialize(new.storage);
});Each Plugin will have a standardized API exposed which the app can utilize via the Storage Manager.
interface StoragePlugin {
get: (keyId: string) => Promise<Blob | string>;
add: (keyId: string, content: Blob | string) => Promise<void>;
remove: (fileId: string) => Promise<void>;
...
}The app can then utilize the storage manager without any issues and having to worry about the nitty-gritty details of the underlying storage APIs.
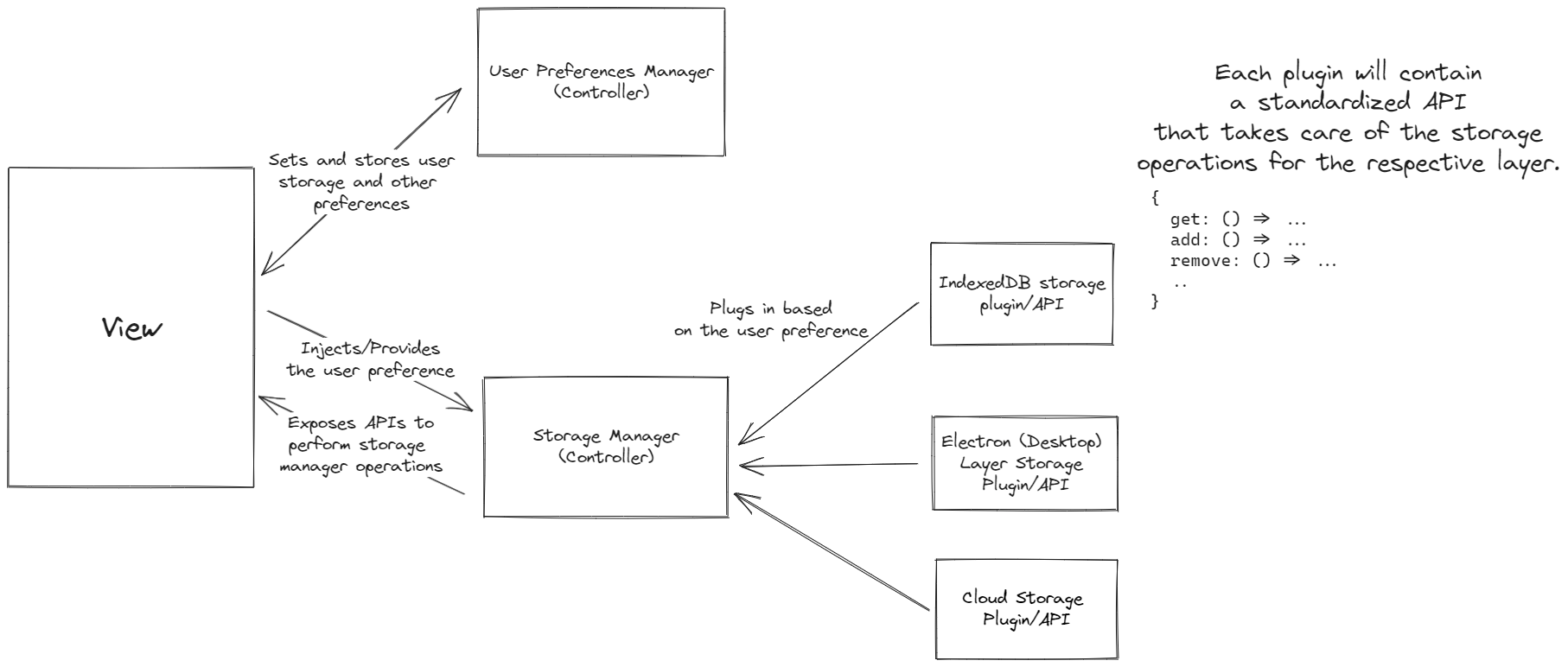
A new storage layer has to be added? Very simply, just add it to the storage manager, provide the user with a choice to switch to it and boom. As long as the plugin and user preferences manager are tested, there's nothing extra that needs to be done! Welcome to extensibility alley! Notice that we only need to use a conditional statement once, and that's at the point of class initialisation, nowhere else is it needed.
The same thing could be done for authentication, users who use the application offline can have a stub authentication plugin that provides placeholder user details, whereas users working with cloud data can sign in and have their credentials retained. The Storage class can then be enabled and disabled at the boundary via the state of the user's authorization info or be injected with the auth class to access what is required.
This simple solution is something that can be applied to a ton of other features. Things that are platform-dependent such as network interfaces can also benefit from such a design, where you can have platform-level checks instead of user preferences to switch between implementation plugins.
Additional Tip: Feature-Flag everything everywhere!
When working on your app and introducing new features, it's very tempting to do an all-or-none feature, either everyone sees it or no one sees it, after all, I've poured my blood and sweat into it, why wait for adoption?
Take it from someone who's built mobile apps for a long time (Not me), you can never have enough feature flags. Not only do they prevent users who shouldn't access a feature from doing so but they act as a safety net, in case something goes wrong and you don't want 100% of your users experiencing the horrors of a crashing app.
Feature flagging also helps establish a boundary between your application's core and the features you build, essentially the features become plugins, only that you have control over whether the plugin is connected or not instead of the end user.
Granted, feature flagging requires some infra-level setup and some additional configuration in your code but that's what this blog post is about, making investments into your app's architecture in the short term to reap the rewards in the long term.
Reaping the rewards
When all is said and done (And for that matter, it's never done), you will realize you have the superpower to swap out parts of your application for a different logic quickly, and to turn on and off features for different users, and treat your app like a set of lego blocks.
Need something? Add it as a plugin, add tests for the plugin, add it to an application boundary behind a flag, run new and existing tests and boom, you're good to go.
In essence, it's a way to decouple what the business needs and what the architecture enables.
We've all seen times when a single small feature that should take 2 days to build and ship end to end takes months simply because the architecture was built with assumptions in mind and was tied to a certain logic (Which often becomes a point of confusion that leads to Engineering managers asking "Wait why is this here and why is this a blocker?" in standups).
A disclaimer: This is obviously not a perfect one-size-fits-all solution to every extensibility problem. It's merely a pattern and the bulk of the work patterns do is enable future extensibility, you might need it, you might not. Evaluate your use case and only then take up the added complexity patterns bring to the table.
Building apps the "right way" is important exactly to remove that confusion from our meetings and our lives as engineers.