
Ever used Pocket? (Well considering you're reading this, I'm sure you do) For people who're constantly working on things and jumping between tasks, it's vital to keep up with the good stuff on the internet. Pocket helps you save blog posts, articles, and basically anything on the internet in your own reading list, it filters out the relevant content on the page and gives a nice reader view for the avid readers out there to mimic a paper feel as well as keep you free from distractions.
In this post, we'll discuss how Pocket does what it does.
Overview of how something like Pocket works
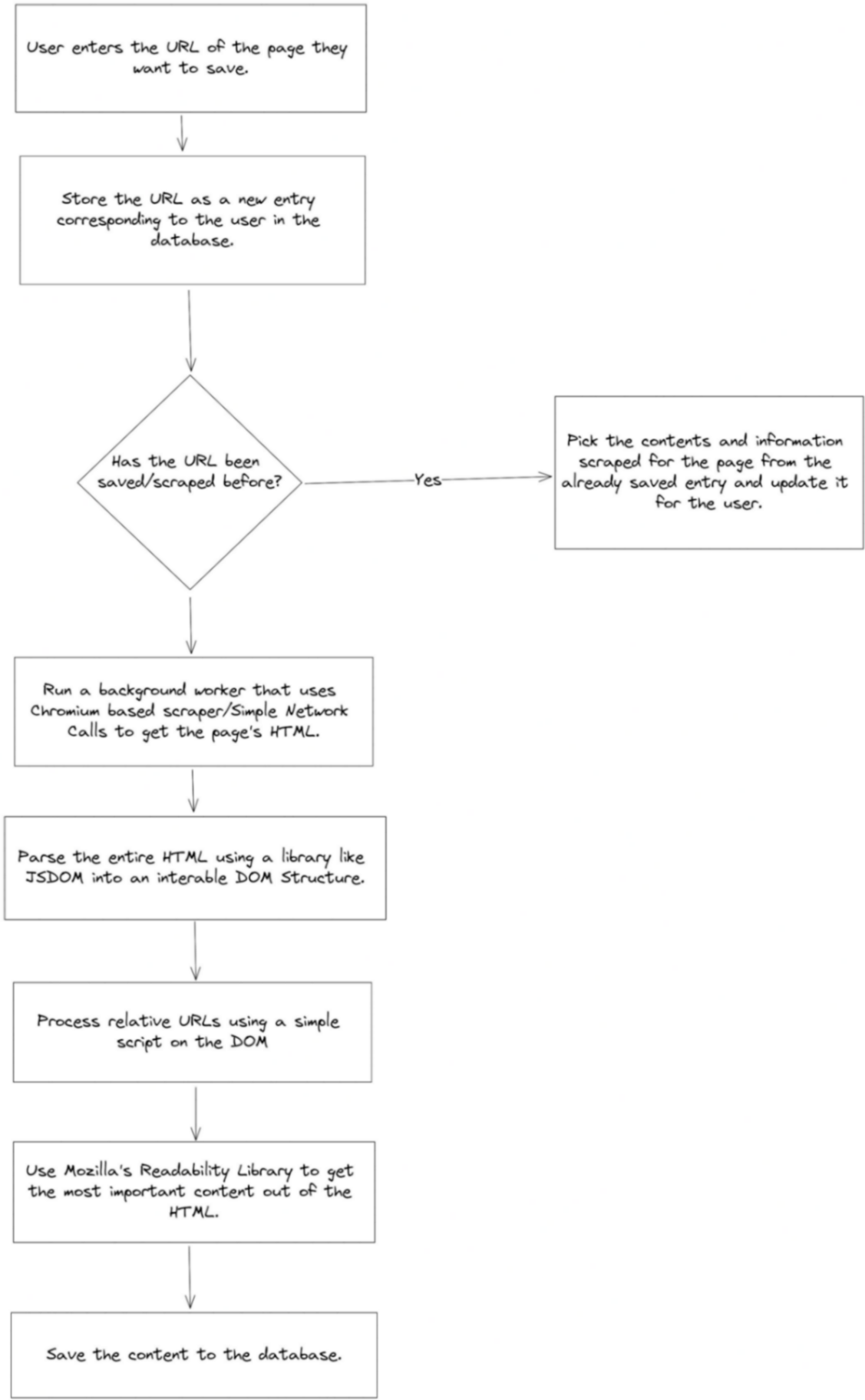
The Readability API to filter relevant content from the page
When Pocket goes and scrapes a page that a user wants to read, its objective is to get the most meaningful content out of the page. To do so, there has to be a scoring mechanism for each part of the page to be assessed and ranked based on the quality of the content. For example, a user doesn't want to see the side navigation bar when they open a page saved on Pocket as it is irrelevant to the main/core content the user wants to read.
Fortunately for us, there is an open-source library for programmers to use to find the most relevant content from a page's HTML. It is called readability and it is (Or at least something similar to it, or something built on top of it) what's used by a lot of services like Pocket.
The readability API is as simple to implement as the following two lines:
const reader = new Readability(document);
const { title, content, textContent, length, excerpt } = reader.parse();How Pocket gets content from a URL
Now that we know how to get the relevant content from a page's HTML, we need to address how to get the HTML in the first place.
Pocket or any other service like it will rely on a mix of two ways to get a page's HTML:
- Use a tool like Puppeteer that can help you spin up a headless Chrome browser on a server, wait for the content of the page to load and give you back everything from a page screenshot to the page's HTML.
- If puppeteer fails or it's known that the site/relevant content the user wants to save is server-rendered, then a simple network call to that page from Pocket's server will do and give us back the HTML. For example, a simple get call with axios for a page will help us:
const html = (await axios.get(url)).data;In an optimization scenario, we can actually make a network call before trying out the puppeteer mechanism. A majority of the pages the user wants to save will be server-rendered (Statistically speaking about the web in general).
In case the readability API does not return content that's longer than a threshold (Which could be either because the main content has not loaded till due to the site being client-side rendered / the site failed to load / the site rejected the network call), then puppeteer kicks in.
How to take care of relative URLs
When you scrape a website, a lot of the URLs in the main content are going to be relative. I.E: Images, videos, and links might have / as their starting characters or ../ in them to signify a directory structure (This is relatively less used today but older websites tend to make use of it a lot).
When you render this HTML in your reader, the assets or links these paths point to would be broken. In such cases, we can write a simple script in order to find any such entries in the DOM and replace them appropriately with the base URL we are currently scraping.
How to scale this beyond a few users
When you work with a small set of users, you don't really have to worry about the number of database documents you're creating in case multiple users save the same link to their reading lists.
But when you are operating at Pocket's scale where you have a ton of users, you'll eventually hit a point where one page is famous enough to have been saved by thousands of users (In fact millions). In such a case you can't create duplicate entries for each user, page content is lengthy many times and you can't afford to have a 10-minute long page saved a million times to your database.
Hence, it's important to decouple the layer that stores the content and metadata for a page and simply have a document referring that a page is in your user's reading list. This mimics the core nature of relational databases where you simply store a foreign key in a table or have a separate table for many-to-many relationships.
This introduces two significant benefits:
- Even if you do decide to scrape the page periodically or after each time 1000 users save a page to their lists, it updates the page content for all other users in case the page's content might have been updated in the background.
- For users, the time from entering the URL to getting a saved preview of the page (That has already been saved by other users before) is so short that it feels instantaneous.
Things to consider
A very important thing to consider is security. When you're scraping HTML off a site and injecting it, you want to be sure that the HTML does not contain any malicious code that can bug the end user. Make sure to purify and sanitize the HTML you get from the website before parsing and saving it into your database.
You also want to set up filters to ensure that your service is not used like a Bookmarking service for anything other than readable content. To do so, make sure to have a minimum threshold for relevant content returned by the Readability API.
Since the end users mostly read when they're on the move. You would also want to make sure the application is offline-tolerant or at least caches the top posts the user has in their reading list offline for them to access whenever they don't have an internet connection.
Highlighting is a great feature Pocket offers, we haven't discussed it in this post but it should be fairly simple to do. The Selection API allows you to detect selections made by a user and listen to them. Since the content you show the end user is static and saved in your database, you can reapply those selections when the user visits the page again.
With that, I hope the post was insightful.